
FilExSec
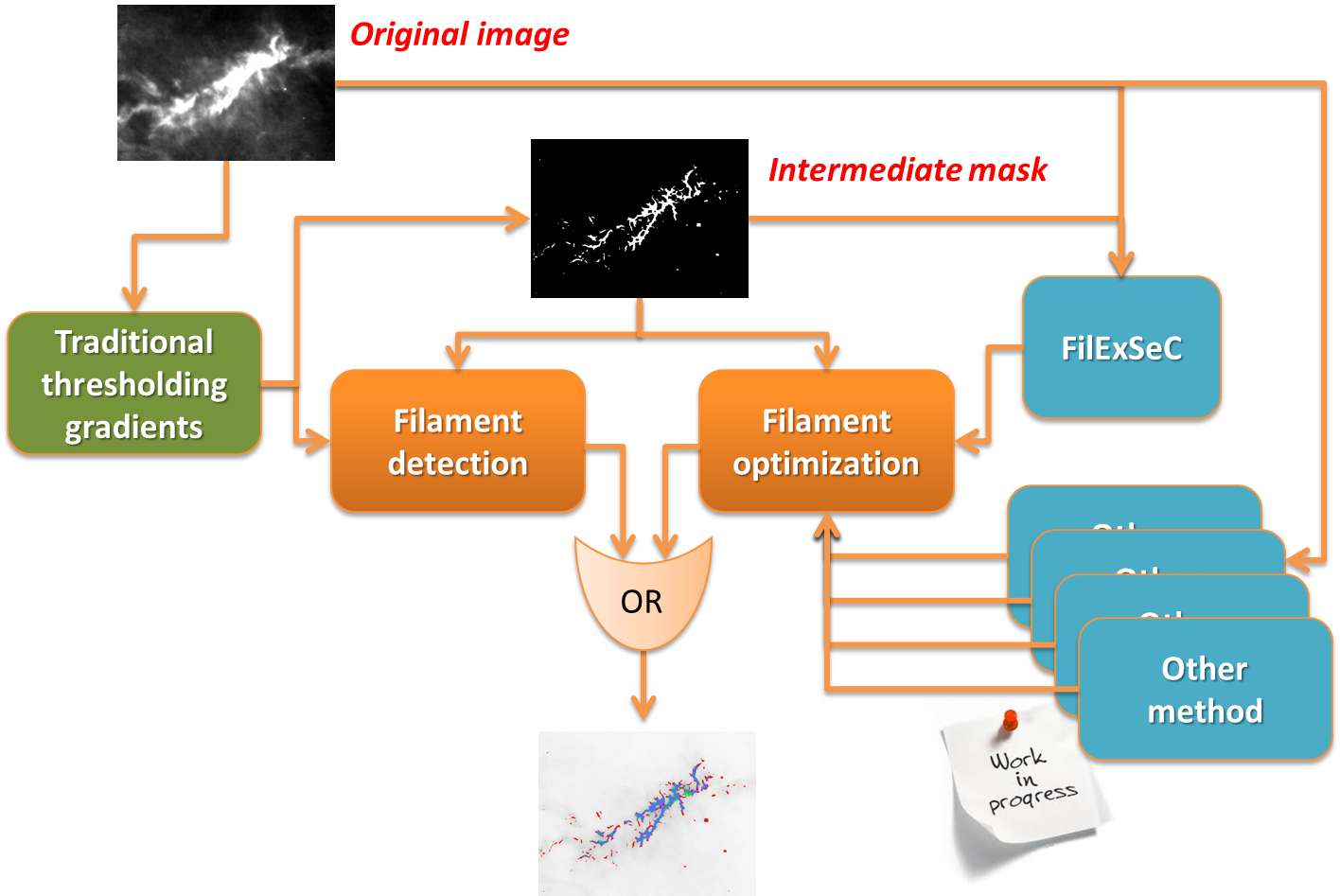
FilExSeC Filaments Extraction, Selection and Classification) is a Data Mining tool created to investigate the possibility to refine and optimize the detection of the edges of filamentary structures present in the Milky Way. It is based on a Feature Extraction module and a Machine Learning (ML) model dedicated to select features and to classify the pixels of an input image.
In principle, each pixel of a given image can belong to a filament or not. Given an input image, it is necessary to associate a set of features to each pixel. According to the parameters defined in the initial setup, it is possible to calculate, for each pixel, hundreds of associated features. This step is named Feature Extraction.
In our approach, each pixel of the input image is identified by means of three groups of features:
- Haar-like features;
- Statistical features.
For most of the extracted features it is expected to have peculiar correlated values (or trends) for the pixels belonging to a filament, although hidden by background noise. These peculiarities can be indeed used by a ML algorithm, hereinafter named as classifier, in order to learn how to discriminate the hidden correlation among filament pixels.
The classifier is based on the supervised ML paradigm, in which the given data sample (hereinafter called KB) is randomly split into training and testing subsets with different percentages, heuristically chosen and with empty intersection. The train set is used to train the model, while the rest of data is used as a blind test set to validate the training. The fitness of the method is indeed evaluated with the blind test set and, if sufficiently good, it is possible to proceed to the next step, i.e. the Feature Selection.
In general, the feature selection is a technique to reduce the initial data parameter space, by weighting the contribution (information entropy) of each feature to the learning capability of the classifier. By minimizing the input parameter space, it is hence possible to improve the execution efficiency of the model, without affecting its performances. In our case, it is reasonable to guess that some of Haar-like and/or statistical features could be considered as redundant parameters, by sharing same quantity of information or in some cases by hiding/confusing a signal contribution.
At the end of the feature selection phase, a subset of features having higher weight (defined as importance) in recognizing filament pixels is considered. This subset is then used to definitely train and test the classifier. At the end of this long-time process the trained classifier can be used to analyse new real images (classification).
Being modular, FilExSeC is easily updatable with different classifiers and/or by defining new features, with minor changes to the processing flow.
FilExSec is ViaLactea Consortium software. Having permissions, you can download the code at the "Project Wiki" page

